You can see and even modify a document file within TCM. With Document Source from the Document menu, the contents of the file, from which the TCM document was loaded, is read into a text edit dialog. You can then view and edit these file contents and save it back to the file (or to another file). You can see the updates when you append or load that file again.
A section starts with a keyword indicating the kind of section and, when there is possibly more than one section of a certain keyword in the same file, it has an identifier which makes the section unique within the file. The rest of the section is enclosed by curly braces. Sections are separated by white space. white space is a sequence of one or more spaces, tabs, carriage-return or newline characters.
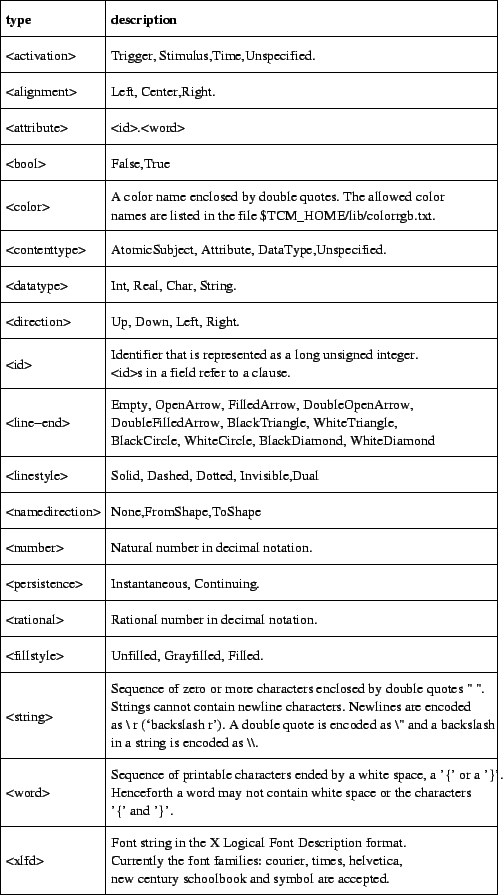
A field is an attribute-value pair enclosed by curly braces. The order of the fields in a section is significant. Attribute values are of one of the types listed in figure C.1. Fields within a section are separated by white space. The attribute name and the value within a field are also separated by white space. Section names and attribute names are case sensitive.
It is possible to include comment text in a TCM file. Comments in a file start with a hash (#). The text in the same line after the hash is comment text and is ignored.
When a file is read, TCM checks the syntax and checks the semantics, i.e. that all required fields are present, that the attribute values have the correct type and it checks references (such as that an edge section has subject fields referring to existing subject sections). TCM reports errors that are found together with a line number in the file where the error is encountered. The errors are displayed in the error log pop-up-window.
Storage
{
{ Format <rational> } # File format, e.g. 1.26.
{ GeneratedFrom <word> }# Tool name and version e.g. TGD-version-1.84.
{ WrittenBy <word> } # Unix login name that has generated this file.
{ WrittenOn <string> } # Writing date/time (in Unix ctime format).
}
Document
{
{ Type <string> } # Document type: e.g. "Generic Diagram".
{ Name <word> } # Document name, e.g. mydocument.gd.
{ Author <word> } # Unix login name of document creator.
{ CreatedOn <string> } # Creation time
# e.g. "Wed Sep 24 15:42:47 MET DST 1997".
{ Annotation <string> }# Free annotation text about this document.
{ Hierarchy <bool> } # For diagram types that allow hierarchic
# documents only: Is this document hierarchic?
}
Page
{
{ PageOrientation <word> } # Portrait or Landscape
{ PageSize <word> } # PageSize: A4, A3, Letter, Legal,...
{ ShowHeaders <bool> } # Show a header on every page?
{ ShowFooters <bool> } # Show a footer on every page?
{ ShowNumbers <bool> } # Show a page number on every page?
}
Scale
{
{ ScaleValue <rational> } # The scale of the diagram. Normally 1.00.
}
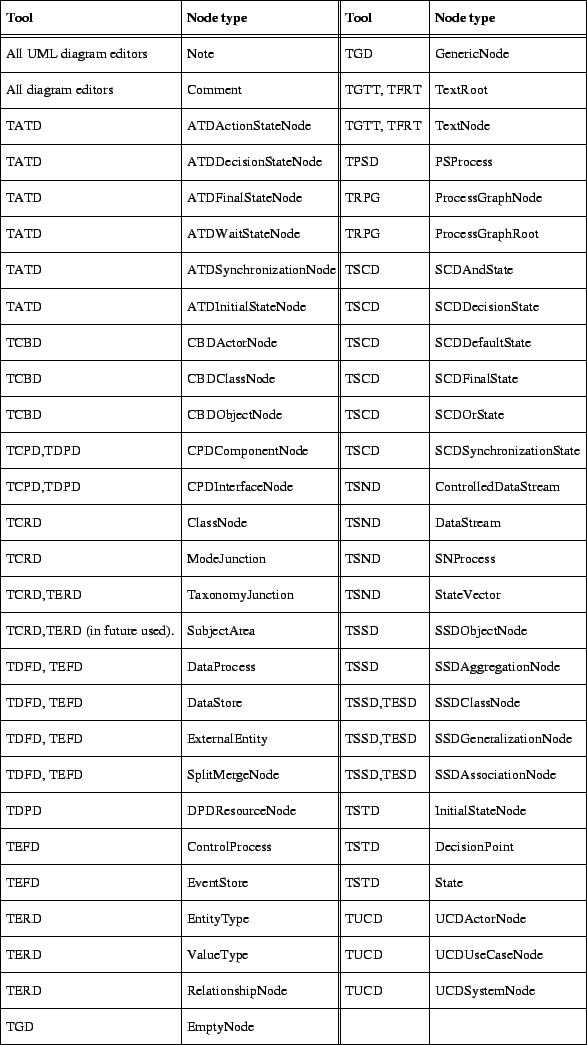
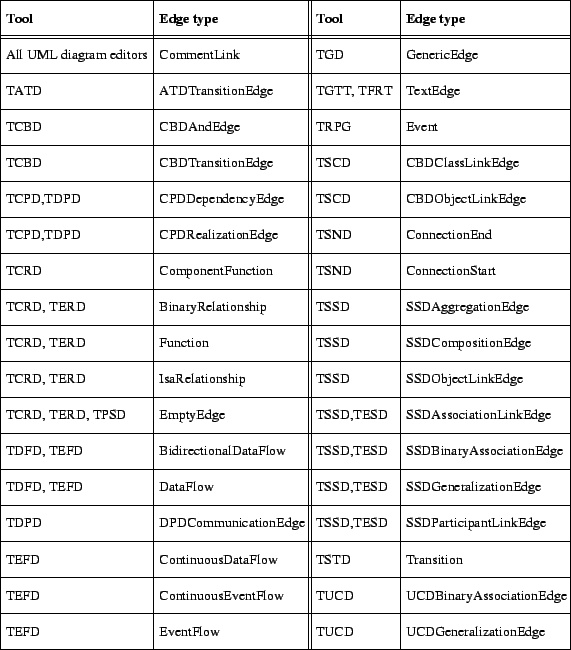
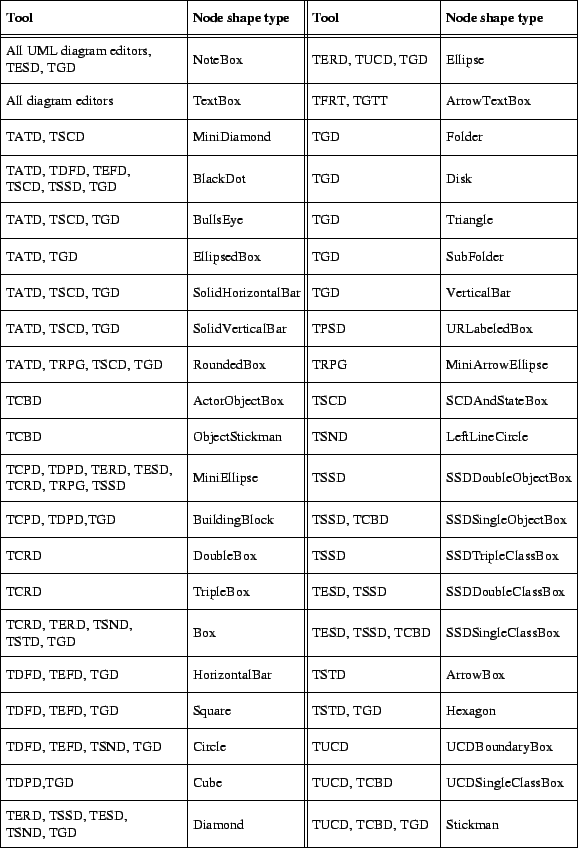
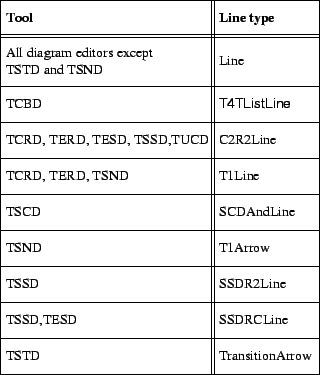
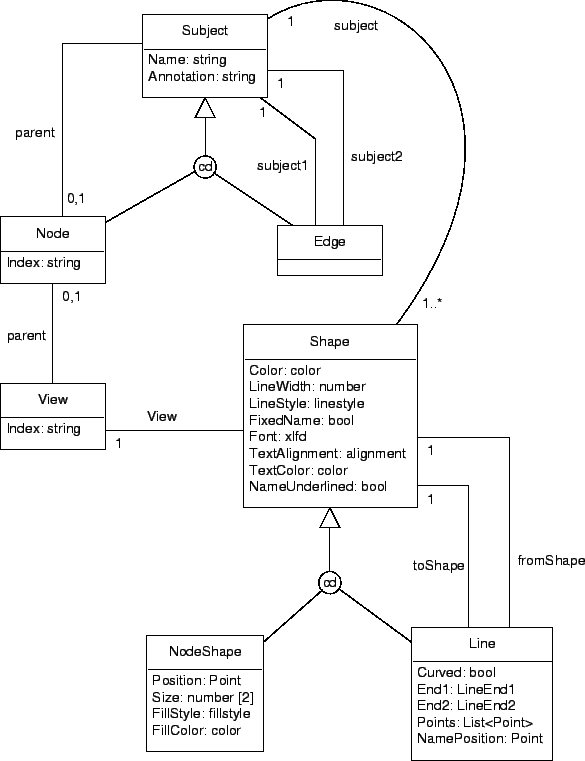
A stored diagram contains a section for each node, edge, view and shape (in no particular order) which follow after the three obligatory storage, document and page sections. Each node type, edge type and shape type section starts with a keyword. A view has the keyword View. In figures C.2 to C.5 you can see which keywords (and accessory sections) are generated and read by which tool. After the node, edge, view or shape keyword there is an identifier which is unique within the file. These identifiers are used for referring from one section to another section. Figure C.6 gives an overview of the global structure of the diagram file format in which file format section types are represented as object classes. The CRD does not show the significant order of the fields in a section. On the other hand, the CRD shows specializations and other relationships between classes and also some cardinality constraints which can not be made explicit in the file format sections. Specific node sections would be subclasses of class Node, specific edge sections would be subclasses of class Edge and specific Shape sections would be subclasses of classes NodeShape or Line.
<NodeType> <id> # e.g. EntityType 123456.
{
{ Name <string> } # name label of the node.
{ Annotation <string> } # annotation text of the node.
{ Parent <id> } # parent node (always 0 in this TCM version).
{ Index <string> } # index label of the node.
# possibly other node attributes
}
The parent field is not used in the current TCM version but it will be used for hierarchical diagrams. In hierarchical diagrams the parent identifier refers to an existing node section. That would mean that a node in a diagram is further specified as a sub-diagram. The newly created nodes and edges in that sub-diagram have that node as parent. Nodes and edges in the top-level diagram have parent 0 (which means they have no parent). Furthermore, in sub-diagrams, shapes representing higher level nodes may also occur. In the generic editor, TGD, these structures will be almost unconstrained. In data flow diagram editors (TDFD and TEFD) and data view editors (TERD and TCRD) these structures are more constrained, for instance only data processes respectively subject areas can be parent nodes and flows respectively relationships have to be balanced. The parent relationship can also used in the tree editors (TFRT, TGTT) but here the entire hierarchy is presented in one view.
When the parent relationship is not used in some editor then the entire diagram is treated as a top-level diagram and the parents of the subjects are always set to 0. In the current version of TCM there are only top-level diagrams so the parent fields are always 0.
Other attributes of node types are:
{ ProcessGroup <bool> } # is data process a process group?
# possibly other data process attributes #
In this version of TCM, the process group field is always False (because
hierarchical DFDs are not implemented yet). When the data process would be
a process group 11.1 then it is parent of a number of children
(processes, stores, flows and/or split-merge nodes.). When the data process
is not a process group then it is a primitive process and then the process
has the following attributes:
{ Persistence <persistence> } # Instantaneous or Continuing
{ Minispec <string> } # Mini specification text
# possibly other leaf node data process attributes #
In this version of TCM it is possible to set the persistence (by default it
is instantaneous) and to edit a minispec text, but they are further not used.
When the persistence is instantaneous then the data process section contains
the field:
{ ActivationMechanism <activation> } # only when Instantaneous
# possibly other discrete leaf node data process attributes #
The activation mechanism can be set in the current
DFD editors (by default it is unspecified). When the instantaneous
data process is activated by a stimulus, the following stimulus field is
added:
{ Stimulus <string> } # input edge name;
# only if activated by stimulus
Otherwise when it is activated by time, a TimeExpression field is given instead:
{ TimeExpression <string> } # only when activated by time
The activation mechanism can also be Trigger. The trigger
edge is then not given in this section but there should be
an input edge labeled `T' to this process.
So it is possible to set the activation mechanism and specify a stimulus or time expression and this information is written to file but it is further not used in the current version of TCM.
{ AtomicSubjects <number> } # number of entities/relationships
{ AtomicSubject <string> } # entities/relationships (>= 1 fields)
In a future version of TDFD and TEFD you will be able to specify the
contents of data stores. For the moment the number of atomic subjects is
always set to 0.
{ ControlProcess <string> }# the control process.
{ Actions <number> } # number of actions of initial state.
{ Action <string> } # initial action (>= 1 action fields).
In the current version of TSTD the name of the control process can
not be specified. So the control process field contains an empty string.
The number of actions specifies how many initial action fields follow.
Actions are arbitrary single line strings (they cannot contain
a newline).
{ Attributes <number> } # number of attributes of class.
{ Attribute <string> } # attribute string (>= 1 fields).
{ Operations <number> } # number of operations of class.
{ Operation <string> } # operation string (>= 1 fields).
The number of attributes specifies how many attribute fields follow
and the number of operations specifies how many operation fields follow.
Each attribute and each operation is a single-line string.
The class nodes in TSSD have after the operations also the following
two attributes:
{ Stereotype <string> } # class stereotype string.
{ Properties <string> } # class properties string.
{ Attributes <number> } # number of attributes of object node.
{ Attribute <string> } # attribute string (>= 1 fields).
Object nodes in TSSD do not have operations.
{ Operator <string> } # process operator, e.g. "*"
{ IsRoot <bool> } # is it a root process ?
{ IsAction <bool> } # is it an action (leaf) process ?
{ Sequence <number> } # sequence number in process tree.
The process operator is always a string of length 1 (when the process
has no operator the string is a single space).
<EdgeType> <id> # e.g. BinaryRelationship 654321
{
{ Name <string> } # name of edge.
{ Annotation <string> } # annotation of edge.
{ Parent <id> } # parent node.
{ Subject1 <id> } # 'departure' subject
{ Subject2 <id> } # 'arrival' subject
# possibly other edge attributes #
}
Edge types also have a parent field which is intended
to be used for hierarchical editors that are still to be build.
For the moment the Parent identifier is always 0.
The Subject1 and Subject2 identifiers should refer to existing
subject sections in this file. It is in principle possible
that and edge (line) connects another edge (line).
At this moment this feature of edge-edge connections is
only available in TGD and in a limited form in TSSD (for
association link edges and connection of notes).
The other attributes of edge types:
{ Constraint1 <string> } # first cardinality constraint.
{ Constraint2 <string> } # second cardinality constraint.
{ RoleName1 <string> } # first role name.
{ RoleName2 <string> } # second role name.
{ Constraint1 <string> } # first cardinality constraint.
{ Constraint2 <string> } # second cardinality constraint.
{ RoleName1 <string> } # first role name.
{ RoleName2 <string> } # second role name.
{ Messages <number> } # number of messages of edge.
{ Message <string> } # message string (>= 1 message fields)
{ Direction <direction> } # message direction (ToShape, FromShape) (>= 1)
{ Flow <flow type> } # flow type (FlatFlow, NestedFlow, Asynchronous) (>= 1)
{ Constraint <string> } # cardinality constraint.
{ RoleName1 <string> } # first role name.
{ RoleName2 <string> } # second role name.
{ Constraint <string> } # cardinality constraint.
{ RoleName <string> } # role name.
{ Event <string> } # event string (including condition).
{ Actions <number> } # number of actions in transition.
{ Action <string> } # action string (>= 1 action fields).
The actions field specifies how many action fields follow.
Each action string is a single line text string.
{ Components <number> } # number of sub-flows
{ Component <id> } # sub-flow (>= 1 component fields)
When the components field is greater than zero then it has for each
component a distinct field.
This component field should refer to an existing data flow edge section.
In the current version of TCM it is not yet possible to specify
the components of a data flow. Therefore the components field is
always 0. When the flow has no components then it has a certain
data contents:
{ ContentType <contenttype> } # AtomicSubject, Attribute,
# DataType or Unspecified
This field is only present when components is 0. This field is by default
unspecified. It is not possible to set this field in the current
version of TDFD or TEFD. When the ContentType is not unspecified then
according to the content type it has one of these three fields:
{ AtomicSubject <string> } # entity type/relationship name.
{ Attribute <attribute> } # attribute of an atomic subject.
{ DataType <datatype> } # values of a simple data type.
But again, these fields cannot be filled in by the current version of TCM.
Therefore data flow sections have no component fields and they have
Unspecified as content type.
{ Components <number> } # number of sub-flows
{ Component <id> } # sub-flow (>= 1 component fields)
View <id>
{
{ Index <word> } # index of hierarchical view.
{ Parent <id> } # the parent node of the view.
}
The index of a view is the same kind of unique index that is used for
data and control processes. The top-level view has index 0. The
children of the top-level view are numbered 1 to n, the children of
non-top-level view x have index x.1 to x.n. Each view, except the
top-level view, has a parent node. The parent field should refer to
an existing node section. The top-level view has as parent 0.
The diagrams of the current version of TCM have only a top-level view.
The indexes of the individual nodes are stored separately in the node
section. The reason is that not all nodes need to have an index, and
in some editors a different naming scheme could be used (for instance,
in TGD, nodes can have an arbitrary index label and in TDFD, data stores
do not have an index label).
The shapes that are contained in the view are not listed in the view section itself. But all shape sections have a reference to the view section in which they are contained.
<NodeShapeType> <id> # e.g. Box 214365
{
{ View <id> } # view in which the shape occurs.
{ Subject <id> } # the node that the shape represents.
{ Position <number> <number> } # center (x,y) position of shape.
{ Size <number> <number> } # width and height of shape.
{ Color <color> } # the line color of the shape.
{ LineWidth <number> } # the line width of the shape.
{ LineStyle <linestyle> } # the line style of the shape.
{ FillStyle <fillstyle> } # the way the shape is filled.
{ FillColor <color> } # the fill color when the shape not unfilled.
{ FixedName <bool> } # string of name-textshape is fixed?
{ Font <xlfd> } # text font of text strings.
{ TextAlignment <alignment> } # multi-line text alignment.
{ TextColor <color> } # the color of the text in the shape.
{ NameUnderlined <bool> } # name-textshape is underlined?
}
Each node shape is contained in an existing view and represents
an existing node. The name label of the node shape is not given
in the node shape section but it is equal to the name of the node
subject, but some other attributes of the labels, i.e. the font and
text alignment are specified in this section.
Node shapes have a (line) color, a text color, and a fill color (only visible with a fill style that is not unfilled). By default the line color and text color are black, the shape is unfilled and the line width is 1.
The node shapes SSDSingleClassBox, SSDDoubleClassBox and SSDTripleClassBox in TSSD and TESD have additionally the following two attributes to indicate whether the stereotype and properties labels of the subject should be shown:
{ ShowStereotype <bool> }
{ ShowProperties <bool> }
<LineType> <id> # e.g. Arrow 563412
{
{ View <id> } # diagram in which the shape occurs.
{ Subject <id> } # edge that the line represents.
{ FromShape <id> } # 'departure' shape.
{ ToShape <id> } # 'arrival' shape.
{ Curved <bool> } # straight (False) or curved (True)
{ End1 <line-end> } # type of line end at departure side.
{ End2 <line-end> } # type of line end at arrival side.
{ Points <number> } # number of line points
{ Point <number> <number> } # line point (>=2 points).
{ NamePosition <number> <number> }# position of name label.
{ Color <color> } # the color of the line (default=black).
{ LineWidth <number> } # the width of the line (default=1).
{ LineStyle <linestyle> } # the style (solid, dashed etc.).
{ FixedName <bool> } # string of name-textshape is fixed?
{ Font <xlfd> } # text font of text labels.
{ TextAlignment <alignment> } # multi-line text alignment.
{ TextColor <color> } # the color of the text (default=black).
{ NameUnderlined <bool> } # name-textshape is underlined?
# possibly other line attributes
}
Each line is contained in an existing view and represents
an existing edge and connects two existing (not necessarily different)
shapes, called FromShape and ToShape.
Both at the beginning point as at the end point of the line there is
some line end which can be some kind of arrow head or
a little circle, diamond or triangle or the line end is just Empty.
The Points field in the line section specifies how many
point fields will follow. A line has at least two points. Each point
has a distinct Point field.
The name position field gives the coordinates of the name label.
The text of this label can be found in the edge section of the subject,
in its Name field. Because the labels of a line can be positioned at free will,
whereas node shape labels can not, only line sections have a
distinct name position field. For the rest, line sections have a number
of fields that also occur in node shape section, like for the colors, text
alignment and line width. Extra attributes for some specific line types are:
{ T1Position <number> <number> } # position of an extra label.
{ T1Position <number> <number> } # position of 1st extra label.
{ T2Position <number> <number> } # position of 2nd extra label.
{ T1Position <number> <number> } # position of 1st extra label.
{ T2Position <number> <number> } # position of 2nd extra label.
{ NameDirection <namedirection>} # direction to read the name.
{ T1Position <number> <number> } # position of 1st extra label.
{ T2Position <number> <number> } # position of 2nd extra label.
{ T3Position <number> <number> } # position of 3rd extra label.
{ T4Position <number> <number> } # position of 4th extra label.
{ NameDirection <namedirection>} # direction to read the name.
These labels can also be positioned at free will and therefore their
positions are saved separately.
{ T1Position <number> <number> } # position of 1st extra label.
{ T2Position <number> <number> } # position of 2nd extra label.
{ T3Position <number> <number> } # position of 3rd extra label.
{ T4Position <number> <number> } # position of 4th extra label.
{ NameDirection <namedirection>} # direction to read the name.
{ Messages <number> } # number of message labels.
{ TnPosition <number> <number> } # position of xth message label.
(>= 1 message label fields)
These labels can also be positioned at free will and therefore their
positions are saved separately.
{ AnchorPoint <number> <number> } # connection point with separator.
{ Separator <direction> } # relative position of separator
{ LineNumber <number> } # line segment to which separator
# belongs (number>=1).
The transition arrow is the presentation of a transition edge in a STD.
The separator field indicates whether the separator is above, below,
to the left or to the right of the transition arrow. When it is to
the left or right, the anchor point is the point where the
separator line is connected to the arrow. When it is above or below,
the anchor point is simply the middle of the separator line. Note
that the length of the separator line is determined by the lengths
of the event and action labels and it is not stored separately.
The line number indicates the line segment to which the
separator line belongs. The highest numbered line segment has
the arrow head of the transition.
Like diagrams, the table editor file format starts first with a Storage section and then a Document section and a Page section. Directly after the Page section follows the Table section with some attributes of the entire table.
Table {
{ TopLeft <number> <number> } # top-left (x,y) of entire table.
{ NumberOfRows <number> } # nr. of rows in table (cells per column).
{ NumberOfColumns <number> } # nr. of columns in table (cells per row).
{ MarginWidth <number> } # min. distance text and column line.
{ MarginHeight <number> } # min. distance text and line.
}
In an earlier version of TCM other attributes where stored as well such
as DefaultLineStyle, DefaultRowAlignment, DefaultColumnAlignment etc. but they are now treated as attributes of the table editor itself
not of a table stored in a file.
Row <number> {
{ Height <number> } # all cells in row have the same height.
{ Alignment <alignment> } # all texts in row have the same alignment.
{ NumberOfCells <number> } # a row having n cells has n+1 lines
... rest of the row attributes.
}
The NumberOfCells of a row has to be equal to the NumberOfColumns field in
the table section. This field indicates how many cells the rows contain.
The rest of the row attributes consist of the attributes of the cells
and lines (line pieces) in a row.
The line pieces to the left and to the right of the cells in a row are seen
as part of the row too. For each line piece a separate line style and width field
are stored. About the cell itself, the cell text string, the fonts
and some annotation text is stored. So for every cell the following information
is stored:
...
{ LineStyle <linestyle> } # Line style of the line piece
{ LineWidth <number> } # Line width of the line piece
{ Text <string> } # texts in a cell.
{ Font <xlfd> } # XLFD font description.
{ Annotation <string> } # annotation text of this cell.
...
}
The size of the cell is determined by the sizes of its row and column. Text alignment of a cell is determined by the combined row and column alignment. In a row section, the two line fields and the three cell fields alternate and, because the number of line pieces is the number of cells plus one, the row always end with two extra fields for the line style and line width of the last line piece.
Column <number> {
{ Width <number> } # all cells in column have the same width.
{ Alignment <alignment> } # all texts in column have the same alignment.
{ NumberOfCells <number> } # a column having n cells has n+1 lines
...
}
The NumberOfCells of a column has to be equal to the NumberOfRows field in the table section. Because the cell texts are already specified in the row sections, a column section only needs the line style and width fields for horizontal line pieces. There are NumberOfCells+1 line style and width fields in a column. Therefore the rest of the column section consists of NumberOfRows+1 times the following two attributes:
...
{ LineStyle <linestyle> } # line style of a line piece
{ LineWidth <number> } # line width of a line piece
...